Fosdem 2015 - samedi: Python, Valgrind, Igprof, LLVMLinux et optimisation de code
This post is part of the "Fosdem 2015" series:
Compte-rendu du Fosdem 2015 jour 2/3 - Python, Valgrind, Igprof, LLVMLinux et optimisation de code
Encore une journée froide, mais sans la pluie et la neige annoncées. Je ne crois pas avoir vu de salles supplémentaires, mais il semble y avoir moins de monde que l’an dernier, du moins dans les couloirs du bâtiment H.
L’organisation est toujours impeccable, que ce soit dans le fléchage mis en place, les conférences, la gestion des flux de personnes dans les salles, l’orientation et l’accueil des visiteurs, les enregistrements ou la sonorisation, un grand merci à eux !
Au menu du Python, du Valgrind, Igprof, LLVMLinux et de l’optimisation de code (superoptimization)
Python & PostgreSQL, a Wonderful Wedding
Même si je n’utilise pas PostgreSQL au quotidien, j’y apprends tout de même que c’est la PEP 249 qui sert de référence pour les modules implémentant des connecteurs avec des bases de données, avec les concepts de connection et de cursor.
Avec son petit nom Python Database API Specification v2.0 c’est tout de suite plus clair.
S’en suit une présentation de plusieurs modules relatifs à PostgreSQL:
Psycopg2
Apparement le connecteur PostgreSQL le plus populaire, en raison de ses nombreuses fonctionnalités (PEP 249 compliant, multi-thread, asynchrone, …) et de sa rapidité, car implémenté en c.
Peewee-ORM
Pour mapper directement des objets sur des bases de données relationnelles, compatible Python2.6+ et Python3.2+ avec une documentation de qualité. On ne gère plus ses objets d’un côté et les requêtes SQL de l’autre, mais on utilise juste les méthodes de ses objets, l’ORM se charge des requêtes SQL:
Mix extrait du quickstart:
|
|
SQLAlchemy
Un autre ORM qui vise clairement l’entreprise, avec de nombreuses fonctionnalités et donc une certaine complexité. Utilise pleinement le modèle objet de Python. A l’opposé de Peewee se veut plus “léger” et flexible.
Alembic
Un projet en beta qui fonctionne avec SQLAlchemy pour migrer des schémas de bases de données.
Ainsi il est possible d’avoir une version A du schéma de ses tables, une version B, avec disons une colonne en plus, et de passer d’une version à l’autre facilement.
Alembic génère des scripts avec les commandes ALTER et autres contraintes nécessaires à la migration d’une version du schéma à une autre. C’est très pratique pour faire la montée de version en parallèle avec l’application qui utilise cette base.
Exemple: mon appli v1 utilise un schéma avec 3 colonnes, mon appli v2 ajoute une colonne, je peux générer un script qui permet de passer du premier schéma au deuxième et inversement.
Du coup je peux monter la version applicative tranquillement d’un côté et la base d’un autre, et de faire un rollback aussi facilement.
Lea, a probability engine in Python
Lea est un package Python pour jouer avec les distributions de probabilités (ou loi de probabilité) de manière intuitive (c’est son but)
Il est possible de modéliser des évènements aléatoires (lancer de dés, de pièce, …) sous forme d’objet, et de les combiner pour créer de nouvelles distributions.
Le module est utilisable en interactif, exemple avec les probabilités des résultats obtenus avec le lancer d’un dé puis de deux:
|
|
- Il est aussi possible de générer des tirages aléatoires avec
.random(), de simuler des tirages sans remise, … - Lea dispose propose aussi un mini-langage leapp (Lea probabilistic programming language), qui est un sucre syntaxique permettant aux non-développeurs d’utiliser Lea.
- Les tutoriels et les exemples montrent bien la facilité de prise en main et la richesse de Lea.
- A noter aussi la gestion des réseaux bayésiens
Tuning Valgrind for your Workload
Si vous développez en c, mais que vous ne connaissez pas le projet Valgrind et sa suite d’outils (memcheck, cachegrind, callgrind, massif, helgrind, DRD), renseignez-vous vite, très vite !
Le but de cette présentation est de comprendre comment ajuster le niveau de détail obtenu pour réduire la consommation CPU/mémoire de Valgrind, mais aussi de gérer les cas particuliers, comme les fonctions récursives et inlines qui rendent difficile l’analyse des stacktraces produites.
Les tests de régression sont un bon cas d’usage: plutôt que de lancer chaque test avec des rapports détaillés en cas d’erreur, il est plus intéressant de lancer rapidement tous les tests avec peu de détails (gain en CPU/mémoire), puis dans un second temps de lancer des analyses plus poussées sur chaque erreur trouvée.
Il existe plus de 150 options permettant ces ajustements. Pour bien en comprendre la portée, il faut un peu comprendre la mécanique interne de Valgrind, notamment sur la méthode utilisée pour vérifier les allocations et accès mémoire.
Après une présentation du fonctionnement de memcheck, qui remplace les appels à malloc(), realloc(), … par les siens pour tracer les allocations mémoires et en déduire les fuites mémoires, le présentateur plonge dans les internals de Valgrind, comme les statistiques internes sur ses zones mémoires et les redzones.
L’interprétation de ces statistiques (--stats=yes) permet de comprendre le surcoût mémoire/CPU engendré pour chaque détail ajouté.
Redzone
Autour de chaque allocation mémoire sur le tas, Valgrind alloue en plus quelques octets avant et après (16 octets par défaut), pour détecter les accès mémoire erronés (buffer overrun et underrun):

Il est possible d’agrandir cette zone tampon pour détecter plus d’erreurs, mais avec un overhead mémoire plus important comme le décrit si bien la doc:
|
|
Les stacktraces
Exemple d’une stacktrace de memcheck:
|
|
Les slides ne montrent pas le côté très vivant de la session: le plus clair du temps était passé en explications et démonstrations dans un shell sur de vrais programmes écrits pour illustrer chaque point, passionant !
Quelques paramètres intéressants:
- —keep-stacktraces=none ne remonte que les erreurs (bien plus rapide)
- —num-callers le nombre de frames de la stacktrace (12 par défaut)
- —merge-recursive-frames regroupe les appels aux fonctions récursives pour garder une stacktrace utile, notamment lors de l’analyse d’une implémentation récursive comme les arbres binaires
Valgrind montre à partir de la version 3.10 les fonctions inline par défaut, comportement modifiable avec —read-inline-info=no
—keep-stacktraces, par défaut à alloc-then-free donne en cas d’erreur de type use after free seulement l’endroit où le bloc mémoire a été libéré.
Avec —alloc-and-free, memcheck conserve en plus l’endroit où l’allocation mémoire a été faite à l’origine. Il est donc plus facile de trouver l’erreur, mais la consommation mémoire de memcheck sera un peu plus importante.
Helgrind
Helgrind est le détecteur de race condition de Valgrind.
Par défaut Helgrind conserve les accès mémoires des 8 dernières frames de chaque thread. Le niveau d’information enregistré est modifiable avec —history-level=none|approx|full et —conflict-cache-size=N
JIT
Là on arrive dans les paramètres avancés, visibles avec —valgrind –help-debug, par exemple —-num-transtab-sectors=NN qui permet de jouer avec la taille du cache d’instructions.
Valgrind et gdb
Une fonctionnalité qui semble peu connue à ma grande surprise, mais tellement pratique !
Illustration: j’ai un programme qui produit une corruption mémoire (segfault) mais seulement au bout de 20min de fonctionnement. En temps normal, le jeu consiste à se rapprocher à coup de breakpoints GDB le plus près possible du problème, à coup d’essais-erreurs, ce qui est horriblement long en plus d’être frustrant.
C’est là que le serveur GDB de Valgrind entre en jeu: dès le premier warning ou erreur détecté par Valgrind, il est possible d’avoir une session GDB dans le contexte de l’erreur.
Dans l’illustration précédente, tout est très simple: il suffit de lancer le serveur GDB de Valgrind, d’y connecter un GDB et de lancer le programme. Dès que l’erreur est détectée, Valgrind stoppe le programme en vous donnant la main dans GDB, vous avez alors le luxe d’être dans le contexte même de l’erreur, ce qui rend le debug bien plus facile.
Il est bien sûr possible de poser des breakpoints ou autre watchpoints au préalable, comme lors d’une utilisation normale de GDB.
La documentation est très explicite.
Exemple rapide sur le programme stringhash
|
|
Ici Valgrind attend qu’un GDB se connecte pour continuer, ce que je fais dans un deuxième shell, en suivant les instructions données:
|
|
Je peux maintenant poser des breakpoints avant de lancer le programme, ou continuer continue. Si une erreur se produit, Valgrind me donnera la main à nouveau dans le GDB du 2ème shell.
IgProf

Photo du LHC
Avec IgProf (The Ignominous Profiler) on ne s’éloigne pas trop de Valgrind, puisqu’il s’agit également d’un profileur mémoire/performance sous licence GPL, dont l’histoire commence en 2003 quand Valgrind n’était pas encore au point.
Développé depuis plus de 10 ans au CERN, il est utilisé pour analyser les programmes qui traitent les énormes quantités de données générées par les expérimentations sur le LHC. Par énorme je veux dire environ 1Pb/s, rien que ça, mais le working set 2011-2013 est de 12Pb.
Je ne sais pas si c’est outil ou la présentation du contexte qui est au final le plus impressionant.
Les programmes analysés par IgProf sont en moyenne comme les données, énormes:
- Des binaires avec des sections de code de 300Mo
- 600 bibliothèques partagées
- 600 000 symboles
- Des piles d’appels à 300 niveaux
- Jusqu’à 1 million d’allocations mémoire par seconde
Contrairement à d’autres outils comme Systemtap, OProfile ou perf, aucun support noyau ni accès root n’est nécessaire. Le public visé n’est pas les développeurs mais les chercheurs.
En interne, ça marche avec les composants suivant:
- Instrumentation dynamique (Dynamic instrumentation)
- Profileur mémoire/performance
- Traitement de la pile d’appels avec libunwind
- Outil d’analyse des dumps igprof-analyse
- Interface web igprof-navigator
Instrumentation dynamique
LD_PRELOAD c’est bien gentil, mais c’est propre à la glibc et limité dans les fonctions qu’il est possible de surcharger.
C’est là qu’intervient l’instrumentation dynamique, qui n’est autre que de l’injection de code pour exécuter des instructions avant une fonction donnée.
Le but est d’injecter dans le préambule de la fonction (là où se font les push des registres) que l’on souhaite intercepter un appel vers du code trampoline, qui lui-même appellera une autre fonction. Ensuite on retourne au déroulement de la fonction initiale.
La slide 24 de la présentation illustre bien le fonctionnement:
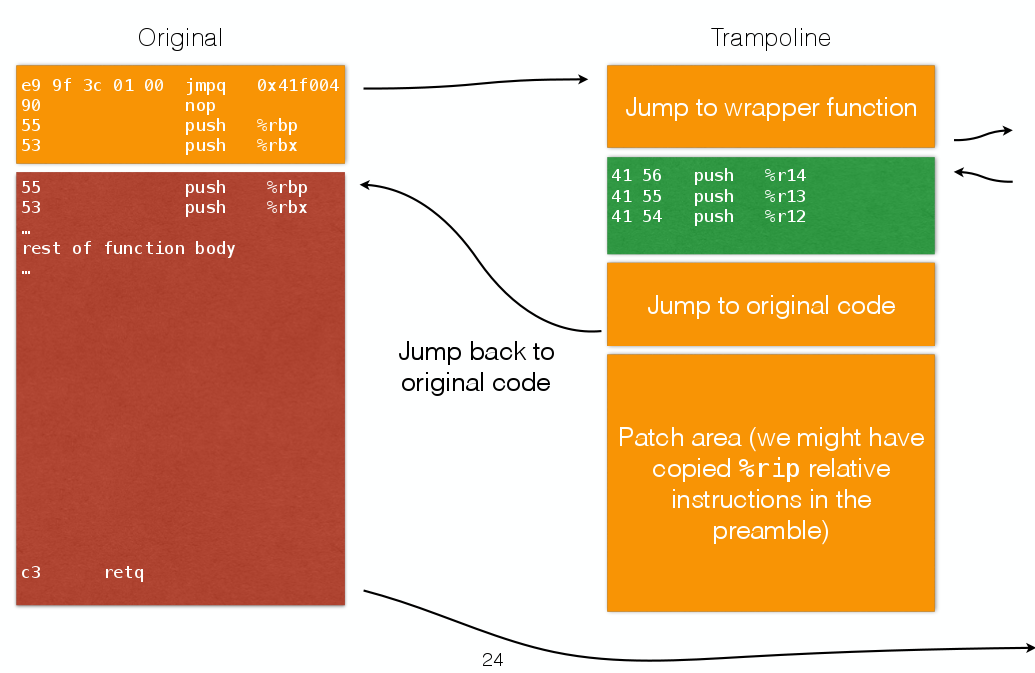
Code trampoline
Profileur mémoire/performances
Une méthode simple et bien connue (surcharge des malloc() et autre par LD_PRELOAD) donnera naissance à MemProfLib
Les hooks sont utilisés pour comprendre les allocations mémoire au complet ou suivant les chemins suivis dans la pile d’appel des fonctions, qui peuvent monter jusqu’à 300 niveaux.
Il y a également une option pour mesurer l’overhead mémoire induit par l’allocation dynamique, invisible pour le développeur. Quand on alloue 3 octets avec malloc(), bien de plus de mémoire est utilisée pour assurer la gestion de ce bloc mémoire et garder des références, sans parler des pages mémoires au niveau noyau, qui sont des blocs de mémoire indivisibles.
En plus de la mémoire, IgProf peut suivre:
- les file descriptors: nombre de lecture/écriture par fichier
- les exceptions c++
- tracer la mémoire allouée mais non inutilisée (avec des motifs “magiques”, si une page mémoire n’a pas été utilisée au moment du free(), le motif de test reste)
Un module optionnel (car il nécessite un support noyau) utilise PAPI (Performance Application Programming Interface) qui est une API d’accès aux compteurs matériels (performance counter hardware)
Récemment Intel a rajouté à ses processeurs des compteurs sur la consommation électrique (RAPL), mais c’est difficilement exploitable, car la consommation électrique est une mesure à faire globalement, et pas seulement au niveau de chaque application.
Le support a été rajouté dans le noyau Linux début 2014 pour l’outil perf.
Analyse des résultats
Mesurer c’est bien, donner du sens aux résultats sans se perdre dans les détails c’est mieux.
L’outil igprof-analyse va dans ce sens, avec une fonctionnalité très utile de manipulation de la pile d’appel des fonctions: il est possible de filtrer des fonctions, d’aggréger des chemins complets (figure ci-dessous), de les renommer (selon la fonction appellante ou pas), pour donner un sens à un ensemble de fonctions.
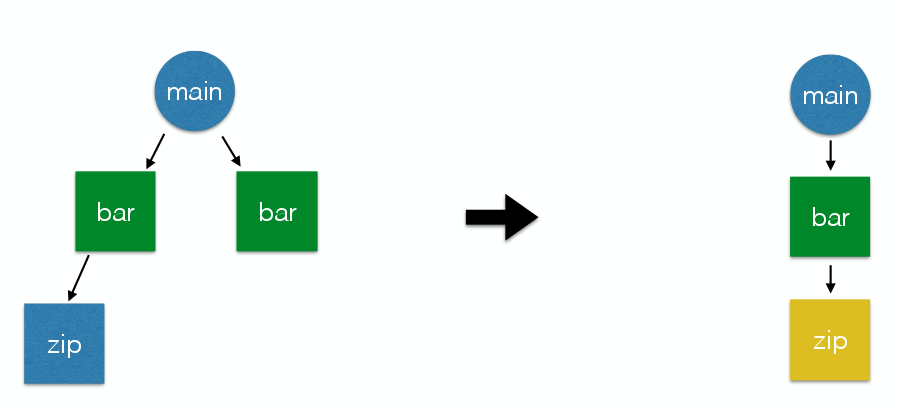
Merge de nodes, slide 57
Pareil avec les bibliothèques partagées, utile dans leur contexte avec plusieurs centaines de bibliothèques.
igprof-navigator est un CGI tout simple pour présenter les rapports sous forme de page web, plus facilement compréhensible par les non-développeurs. Quelques exemples de rapports sont en ligne ici et là
Superoptimization
(Dans cet article quand je parle d’instruction je parle d’une instruction en langage assembleur)
Les options d’optimisation des compilateurs modernes (-O0, -O2 de gcc par exemple) sont capable de produire un meilleur code binaire que le code généré sans ces options.
Le but de la super optimisation (en: superoptimization) n’est pas de produire un meilleur code mais un code optimal, en étant le plus rapide, le plus court ou le plus efficient au niveau de la consommation électrique qu’un code directement sorti d’un compilateur standard.
Un cas concret montré durant la présentation: une séquence de 18 instructions pour tester si un nombre est une puissance de 2 peut être réduit à 2 instructions.
Cette technique datant de la fin des années 1980 (1987: Superoptimizer: a look at the smallest program) n’est pas vraiment nouvelle, et à l’époque les gains étaient déjà importants: un code en assembleur optimal peut être 25% plus rapide qu’un code écrit par un développeur expert, et jusqu’à 40% plus rapide qu’un code généré par un compilateur.
Le principe est de chercher, pour une séquence d’instructions donnée, la meilleure séquence équivalente possible par recherche exhaustive. Cette recherche étant coûteuse, elle reste réservée aux séquences de code critiques.
GNU superoptimizer est une implémentation de cette technique.
Exemples d’étapes mises en oeuvre:
- Recherche des séquences de code optimisables (des séquences courtes, car le processus est coûteux)
- Suppression des instructions inutiles (exemple
mov r0, r0) - Canonification: pour une séquence de code donnée, remplacement des différentes formes par une forme canonique (réduction du nombre de registres utilisés)
- Recherche de séquences d’instructions qui peuvent être remplacées par des séquences plus courtes ou plus rapides (peephole optimization)
Exemple de l’échange du contenu de 2 registres, la version de départ utilise 3 registres, la version optimale n’en n’utilise que 2 (tiré de Automatic Generation of Peephole Super optimizers)
|
|
Pareil avec l’opération eax = ecx - eax - 1
|
|
Une instruction de gagnée !
Dans la vraie vie OpenSSL a profité dans une fonction critique d’un gain de 16 instructions sur 116 (7.25%) et un gain en vitesse de 60% (Stochastic Superoptimization)
Autres notes:
- La recherche de séquence optimales est rendue difficile par le pipelining des instructions dans les processeurs.
- Sur les processeurs de type RISC, les séquences d’instructions optimisables sont plus longues et moins nombreuses.
- Inversement, sur les processeurs de type CISC, les séquences d’instructions optimisables sont plus courtes et plus nombreuses.
- Pistes d’évolution de la superoptimisation: le machine learning, la parallélisation.
La superoptimisation va sans doute gagner en popularité dans un avenir très proche, avec la consommation électrique qui devient un enjeu majeur avec la multiplication des objets connectés.
Autre lien: Superoptimizing Compilers: Etude complète de faisabilité
LLVMLinux
Cette présentation parlait des avantages à utiliser les outils de la suite LLVM avec le code du noyau Linux, dont évidemment le compilateur et l’assembleur.
Le noyau peut en théorie être compilé avec make CC=clang mais je n’ai pas encore eu le temps de tester.
Se passer de GCC c’est bien, mais quels sont les avantages ? Les voici:
- La compilation du noyau est plus rapide.
- License BSD (troll)
- LLVM comporte un analyseur de code statique.
- Une interprétation différente des undefined behavior du standard C, pour repérer des bugs possibles à la compilation (Introduction intéressante au concept)
- De repérer et de supprimer les extensions GNU devenues inutiles.
- L’assembleur étant intégré dans clang, l’interaction est plus rapide, plus strict, et les messages d’erreurs plus précis.
- clang valide l’assembleur embarqué dans le code C, au contraire de GCC.
- clang 3.6, comme GCC 5, est valide C11. Une fois de plus cela permet de croiser les warnings/erreurs trouvées par l’un ou l’autre.
Pretty-printing kernel data structures
Ici on parle de CTF (C Type format) qui est une alternative plus compacte au très répandu DWARF, et initialement développée dans DTrace.
La présentation se déroule autour de l’utilisation de CTF dans le debuggeur noyau DDB, disponible sur les systèmes FreeBSD/OpenBSD/NetBSD/Mac OS X. Il faut voir DDB comme un outil très bas niveau, un peu rustre mais qui fonctionne toujours.
Le problème résolu par CTF est de rendre plus agréable l’affichage des structures noyau complexes (buffers, file, listes chaînées, …) dans DDB (complétion avec tab, indentation correcte des structures imbriquées, afficher une structure sans devoir la caster soi-même, …)
J’ai trouvé le sujet très intéressant car c’est un problème qui me parle, et j’aurai bien aimé avoir ces facilité lorsque j’ai trouvé/fixé mon premier kernel panic sous FreeBSD. C’est déjà assez difficile de travailler dans l’espace noyau, alors si en plus les outils n’aident pas…
L’auteur du projet fait les choses bien: son implémentation de CTF vise le multi-plateforme et l’utilisation possible en userspace, tout comme les outils ctfconvert, ctfmerge et ctfdump.
Son blog permet de voir les questions qu’il s’est posé durant le développement.
Et c’est ainsi que s’achève la journée du samedi, avec tout un lot de cruels dilemmes au moment de choisir les conférences…