First, I will introduce the patchfile format, then how to split up a patch up into multiple patch files, either by filenames or hunks.
I’m going to use the term patchfile for the output of the diff(1) command, which filenames are usually .diff suffixed, eg mypatch.diff
What is a patchfile?
When comparing 2 files, the diff(1) command tries to record differences as groups of differing lines, and uses common lines to anchor these groups within the files. Such groups are called hunks of difference.
Example of a patchfile with 3 hunks (they are prefixed by @@):
$ diff -u group.orig group
--- group.orig 2014-02-04 19:38:20.800277081 +0100
+++ group 2014-02-04 19:38:33.366452009 +0100
@@ -1,5 +1,4 @@
root:x:0:root
-bin:x:1:root,bin,daemon
daemon:x:2:root,bin,daemon
sys:x:3:root,bin,user1
adm:x:4:root,daemon
@@ -7,8 +6,6 @@
disk:x:6:root
lp:x:7:daemon,user1,user2
mem:x:8:
-kmem:x:9:
-wheel:x:10:root,user1
ftp:x:11:
mail:x:12:
uucp:x:14:
@@ -17,8 +14,6 @@
locate:x:21:
rfkill:x:24:
smmsp:x:25:
-http:x:33:
-games:x:50:user1,user2
lock:x:54:
uuidd:x:68:
network:x:90:user1,user2
You have noticed an extra header line:
--- group.orig 2014-02-04 19:38:20.800277081 +0100
+++ group 2014-02-04 19:38:33.366452009 +0100
Because a patchfile can contain differences of several files, each set of hunks starts with a similar two-line header, to indicate the source and the modified file to which the next hunks are related to. The timestamps are the modification time of each file.
The patchfile above is in unified format (diff -u option), bigger than the default normal context format below, but it adds the context lines needed by patch(1) to correctly apply the patchfile.
$ diff group.orig group
2d1
< bin:x:1:root,bin,daemon
10,11d8
< kmem:x:9:
< wheel:x:10:root,user1
20,21d16
< http:x:33:
< games:x:50:user1,user2
The meld GUI tool helps to clearly outline the 3 hunks:
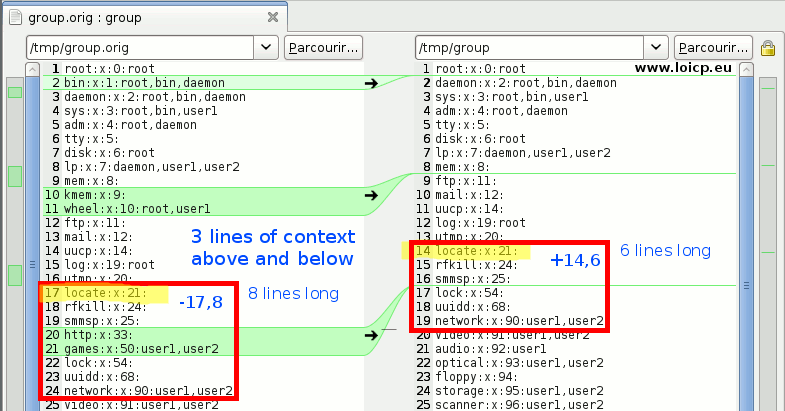
Description of the hunk header, with the 3rd hunk:
@@ -17,8 +14,6 @@
- -17 : from file (/tmp/group.orig), hunk context starts from the 17th line
- ,8 : the hunk is 8 lines long
- +14 : to file (/tmp/group), hunk context starts from the 14th line
- ,6 : the hunk is 6 lines long
The context becomes obvious: 3 lines around the differences, this is the default diff(1) context.
Extracting hunks
The patch command does not allow to select the hunks to apply, only all hunks as a whole. Given the above example, it’s not possible to only apply the third hunk or only the first one.
However it’s sometimes handy to apply:
- Only the huks related to a specific set of files
- Only the hunks related to cosmetic changes
- For a specific file, only the last hunk
I’ve still not found a way to do that directly with the patch(1) and diff(1), but I’ve found a trick: splitting out the hunks of a patchfile to separate files, one per hunk, or one per patched file.
Splitpatch is a tool to automate this process.
Splitpatch
Let’s take a realworld example from CFEngine repository:
- First grab splitpatch, and read its documentation:
$ wget https://raw2.github.com/benjsc/splitpatch/master/splitpatch.rb -O splitpatch
$ chmod +x ./splitpatch
$ ./splitpatch --help
splitpatch splits a patch that is supposed to patch multiple files
into a set of patches.
Currently splits unified diff patches.
If the --hunk option is given, a new file is created for each hunk.
If the --fullname option is given, new files are named using the
full path of the patch to avoid duplicates in large projects.- Fetch the patchfile we are going to use, and try to get some information thanks to diffstat(1)
$ wget https://github.com/cfengine/core/commit/6a2972ab804e903051987564e5c9a4182bcc5c6f.patch -o original.diff
$ diffstat original.diff
libpromises/evalfunction.c | 101 ++++------
libutils/string_lib.c | 7
tests/acceptance/01_vars/02_functions/readstringarrayidx.cf | 59 +++++
tests/acceptance/01_vars/02_functions/readstringarrayidx.cf.txt | 4
4 files changed, 116 insertions(+), 55 deletions(-)The original.diff patchfile affects 4 files, with certainly many hunks, but it’s hard to be more precise without having a look at the file.
- Split original.diff into a set of patchfiles, grouped by file modified:
$ ./splitpatch original.diff
File null.patch already exists. Renaming patch.
loic@iron[0]: ~/tmp/patch
$ ls -1
evalfunction.c.patch
null.patch
null.patch.0
original.diff
splitpatch
string_lib.c.patch- Check some patchfiles to verify they are each one related to only one file:
$ diffstat evalfunction.c.patch
libpromises/evalfunction.c | 101 ++++++++++++++++++++++-----------------------
1 file changed, 50 insertions(+), 51 deletions(-)
$ diffstat string_lib.c.patch
libutils/string_lib.c | 7 +++----
1 file changed, 3 insertions(+), 4 deletions(-)It is even possible to get a separate patch for every hunk of original.diff:
$ ./splitpatch --hunks original.diff
File null.0.patch already exists. Renaming patch.
$ ls -1
evalfunction.c.0.patch
evalfunction.c.1.patch
evalfunction.c.2.patch
evalfunction.c.3.patch
null.0.patch
null.0.patch.0
original.diff
splitpatch
string_lib.c.0.patch
string_lib.c.1.patch
string_lib.c.2.patchThe 4 hunks related to the evalfunction.c file are now available separately (evalfunction.c.0.patch, evalfunction.c.1.patch, …)
What about null.0.patch. files? Sounds weird, because the original.diff patchfile doesn’t affect any null file, so, from where do they come from? It happens when the patch is meant to create a new file, so the from file is /dev/null. The header of null.0.patch is self-explaining:
$ head -2 null.0.patch
--- /dev/null
+++ b/tests/acceptance/01_vars/02_functions/readstringarrayidx.cfGit patch mode
The patch mode of git-add(1) looks a bit overkill, but is a powerful tool and does the job. The idea is to selectively stage the hunks one by one, then to use git diff to generate a set of patchfiles.
Here is a good introduction to Git patch mode, so I’m not going to paraphrase it here.